Hosting WordPress preinstallato e gestito con il 50% di sconto. Scopri la promo
In alcuni casi, le pagine web che pubblichi sul sito non hanno alcun valore per il motore di ricerca ma solo per l’utente. In queste circostanze può essere utile utilizzare il tag noindex per evitare l’inserimento nella serp. Considerando le varie fasi di Google, avviene la scansione ma non l’indicizzazione della risorsa segnata

Questo meta tag robots, vale a dire una serie di direttive che si inseriscono nella sezione head del codice HTML di un sito internet, può essere una risorsa preziosa al pari di altre caratteristiche di una pubblicazione come il nofollow, l’hreflang e il rel canonical. Vuoi scoprire di cosa si tratta il noindex e come si usa online?
Argomenti
Il robots noindex è un meta tag – ovvero un’istruzione rivolta al motore di ricerca e non visibile all’utente – che consente di non indicizzare la risorsa. Di default, le impostazioni di una pubblicazione sono index, quindi indicizzabili.
Nel momento in cui si aggiunge quest’istruzione – ci sono diversi modi per farlo – si suggerisce al motore di ricerca di non considerare la pagina web e di escluderla dall’indicizzazione.
Ricordiamo che il meta tag robots noindex è rispettato da quasi tutti i motori di ricerca che osservano il comando: il crawler visita e scansiona la pagina, ciò che puoi impedire è l’inclusione della risorsa nell’indice dei risultati. Ecco un esempio di come appare il meta tag robots noindex su una pagina internet:
<meta name='robots' content='noindex, nofollow' />In questo caso, il noindex si accompagna con il nofollow che suggerisce di non seguire i link inseriti nella pagina web. Inoltre, non bisogna confondere con il disallow del robots.txt. Ma per approfondire questo punto ti consiglio di dare uno sguardo al prossimo paragrafo che spiega proprio la divergenza tra questi elementi.
Da leggere: cancellare una pagina da Google
A primo impatto, il tag noindex potrebbe essere confuso facilmente con il comando disallow del robots.txt. Ovvero il file che include una serie di indicazioni utili per gestire l’accesso ai crawler dei motori di ricerca (non solo del Googlebot) per le varie aree del sito web. Ebbene, ci sono delle differenze sostanziali.
In primo luogo, il robots.txt incide sulla scansione e non sull’indicizzazione. Ciò significa che agisce a un livello superiore del meta tag robots noindex: se c’è disallow di una cartella, questa non viene neanche scansionata mentre il noindex include questa possibilità evitando però che la risorsa sia indicizzata da Google.
Questo significa, in buona sintesi, che è inutile intervenire sia su robots.txt che sul meta tag robots e inserire una pagina sia in disallow che in noindex. Usare entrambe le risorse può portare a conflitti e a relativi problemi su indicizzazione: se il noindex deve essere seguito, c’è bisogno che la risorsa venga scansionata.
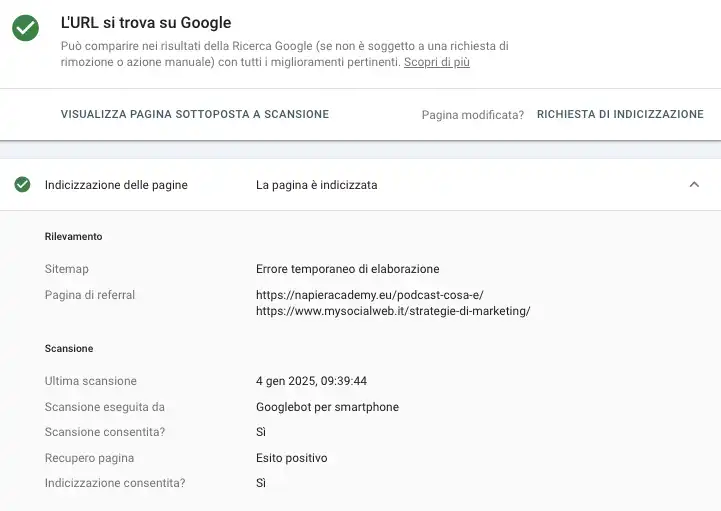
Come scoprire se una pagina è in noindex? Puoi utilizzare il tool della Search Console per scansionare il documento e verificare se è indicizzato o meno, e se c’è presenza del meta tag. Per avere una lista completa di tutte le risorse in noindex puoi utilizzare una scansione di Screaming Frog che simula il crawler.
Il meta tag noindex viene utilizzato dai webmaster e dagli esperti SEO per evitare che i motori di ricerca inseriscano negli indici delle pagine che non devono essere considerate. Perché magari hanno poco valore o possono essere considerate scadenti a causa di un gran numero di User Generated Content. Ad esempio?
Puoi mettere in noindex pagine di ringraziamento o di acquisizione lead. Oppure, il noindex si usa quando hai delle risorse che si possono ottenere dopo aver lasciato il contatto email, delle landing page da utilizzare solo per l’advertising o delle categorie di articoli del blog utili solo all’utente e che non hanno valore in termini SEO.
Il meta tag robots noindex può essere molto utile per evitare che si indicizzino singole pagine web ma un uso poco attento può portare a diversi problemi di visibilità. In primo luogo, se mettiamo in noindex pagine che portano traffico organico grazie al ranking o che ricevono backlink remiamo controcorrente.
E tendiamo a eliminare tutti i benefici legati al posizionamento e all’attività di link building o earning. Quindi, è importante utilizzare il noindex solo quando serve. Se per caso hai inserito questo meta tag per errore puoi ripristinare il risultato eliminando il comando e chiedere una scansione della risorsa su Search Console.
Tra gli errori comuni c’è l’inclusione di questo meta tag robots su pagine archivio che Google utilizza per scoprire altre risorse, come avviene per le categorie. Quali pagine devono stare in noindex? Spesso si mette questo comando sui tag del blog: io preferisco lasciare indicizzati quelli che hanno un valore SEO ed eliminare i tag inutili, e mettere in noindex le pagine archivio superflue come avviene in alcuni casi per gli autori.
Inoltre, per i contenuti duplicati conviene usare il rel canonical al posto del noindex in modo da far capire a Google qual è la risorsa da preferire. In linea di massima, l’idea è quella di lasciare scansionare il più possibile e limitare l’uso del noindex solo per i casi specifici. Aiutando anche a ottimizzare il crawl budget del sito web.
Ci sono diversi modi per implementare questo comando e inserire il meta tag robots noindex su una pagina web o una determinata sezione di archivi su un blog WordPress. In primo luogo, possiamo semplicemente aggiungere il seguente codice nella sezione head della pagina web che vuoi escludere dall’indice:
<!DOCTYPE html>
<html lang="it">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="robots" content="noindex">
<title>Titolo della Pagina</title>
</head>
C’è un’alternativa? Certo, c’è l’opzione X-Robots-Tag. Puoi configurare il server web per inviare l’istruzione noindex tramite l’intestazione HTTP. Questa opzione può essere utile, come suggerisce anche Google, per intervenire su file differenti come PDF, immagini e video. Ecco una soluzione Apache, tipica di WordPress:
<Files "file-da-non-indicizzare.pdf">
Header set X-Robots-Tag "noindex, nofollow"
</Files>
Altra soluzione molto conveniente: utilizzare un plugin come WordPress SEO by Yoast che trovi anche nell’installazione hosting WordPress di Serverplan. Questo piano hosting, con il CMS già pronto e in versione italiana, ha già tutti i plugin per iniziare a lavorare con il tuo sito web. Compreso l’ottimo plugin di Joost de Valk.
In questo caso, alla fine dell’articolo trovi un box con le impostazioni base come tag title e meta description. In basso c’è la sezione delle impostazioni avanzate: qui puoi decidere se inserire o meno il noindex intervenendo sulla voce “Vuoi permettere ai motori di ricerca di mostrare questi contenuti nei risultati di ricerca?”.
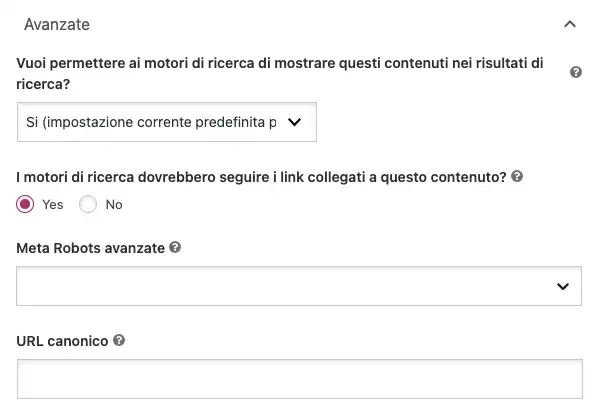
Impostando questa sezione sul No inserisci il noindex. Ricorda che nelle impostazioni base di Yoast puoi aggiungere questo meta tag robots di default su tutte le sezioni del sito, comprese le pagine archivio degli autori o dei tag e delle categorie (opzione che non ti consiglio per evitare gravi problemi di indicizzazione).










