Quando si parla di meta tag robots il rischio è quello di confonderlo con il robots.txt. Sono due elementi differenti che svolgono una funzione simile: comunicano con Google. Danno indicazioni al motore di ricerca.

Lo fanno con metodi diversi per soddisfare funzioni specifiche dell’ottimizzazione SEO. Per un webmaster è importante poter lavorare con la massima flessibilità e autonomia questo punto. Chi si occupa di search engine optimization deve essere in grado di suggerire a Google come comportarsi di fronte a una risorsa.
Se seguirla o meno. E se dare importanza i link inseriti. Questo è decisivo, importante per la gestione della tua presenza online. Ecco perché ho pensato di dare qualche riferimento utile rispetto al meta tag robots, una stringa di testo che non si vede nella pagina restituita dal browser. Ma può fare tanto per l’equilibrio del sito web.
Argomenti
Si tratta di un meta tag che controlla il comportamento della scansione per suggerire noindex e nofollow. Questa stringa di codice rientra nell’elenco dei comandi ufficiali proposti da Google.
Detto in altre parole, il meta tag robots viene usato per comunicare con i programmi che si occupano della scansione del sito web.
Mentre, ad esempio, la description suggerisce un testo per introdurre il contenuto del documento da inserire nella serp, il meta tag robots dà notifiche rispetto ai parametri della pubblicazione.
Questa stringa può controllare l’indicizzazione di una risorsa. Il vantaggio: puoi attivare dei processi specifici, non operazioni di massa ma puntuali e certosini per regolare un passaggio decisivo: come Google debba vedere una singola pagina. Qualche dato in più?
Da leggere: cosa fare quando il sito non si vede su Google
La posizione dei meta tag è la sezione header del documento HTML. In questo modo si convalida la presenza di queste istruzioni e i vari crawler possono leggere le indicazioni del webmaster e agire di conseguenza.
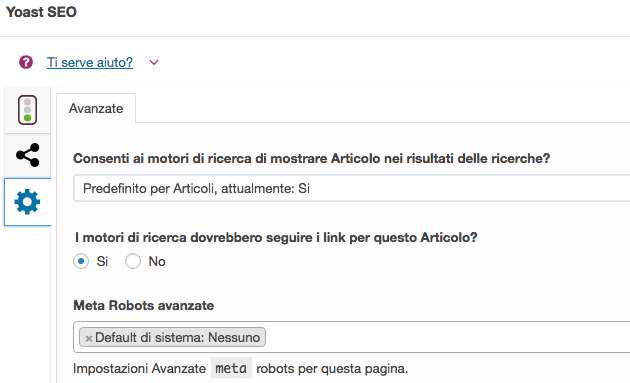
Per modificare l’elemento senza intervenire sul codice puoi usare WordPress SEO by Yoast che nelle funzioni avanzate permette di modificare la visibilità di una pagina tramite un menu a tendina (esempio in alto).
Ovviamente è un approccio limitato ma semplice e veloce. Non a caso abbiamo deciso di includere questo plugin nell’hosting gestito con WordPress preinstallato: basta un click per avere tutto quello che ti serve, anche la migliore estensione SEO che ti consente anche di modificare il meta tag robots su post e pagine WordPress.
Hosting WordPress preinstallato e gestito
Il modo migliore per capire cos’è il meta tag robots in questo contesto? Mostrarlo con un caso concreto. Forse hai già visto una stringa del genere, ecco un esempio preso dalla guida ufficiale Google:
<!DOCTYPE html>
<html><head>
<meta name="robots" content="noindex" />
</head>
<body>(…)</body>
</html>
In grassetto c’è il meta tag robots, composto da due elementi: il valore dell’attributo (name) e il tipo di comando da attribuire al documento (content). In questo caso si è indicato che il comando vale per tutti i crawler.
<meta name="googlebot" content="noindex" />
Così, invece, l’indicazione vale solo per un determinato programma di scansione, vale a dire il bot principale di Google. Il resto degli spider viene esonerato dal comando che stai proponendo per la singola pagina.
Il tag robots viene preso in considerazione dopo l’OK del robots.txt. Se quest’ultimo impedisce la lettura della pagina, le informazioni successive sono ignorate. Queste sono delucidazioni che i motori di ricerca possono prendere in considerazione ma non dei blocchi sicuri. Se hai delle informazioni riservate che non vuoi far indicizzare conviene usare una password per proteggere l’accesso.
Il tag title mi aiuta a comunicare il topic, la meta description si occupa della descrizione. Il tag keyword non serve a niente. E il robots? Qual è il suo compito? Comunica al motore di ricerca come comportarsi con:
Questi sono i comandi principali. I valori predefiniti sono attivi (index e follow), Google riconosce più valori per ogni comando, basta separarli con virgola. Non vengono influenzati da maiuscole o minuscole. Esempio?
<meta name="robots" content="noindex, nofollow" />
La pagina web è praticamente inesistente. O almeno questa è la richiesta del webmaster ai crawler dei motori di ricerca. Ma non esistono solo i comandi per non far indicizzare una pagina o mettere i link in nofollow.
<meta name="googlebot" content="noindex">
<meta name="googlebot-news" content="nosnippet">
Per comunicare le preferenze a due spider differenti devi usare due comandi diversi su righe consecutive. Sopra trovi un esempio della sintassi per scrivere un meta tag robots dedicato a due software differenti.
Come già detto, ci sono diversi comandi che puoi inserire in questo elemento del codice HTML per gestire la relazione tra motore di ricerca e pagina web. Ecco la lista delle possibilità che puoi prendere in esame.
all | Valore predefinito. Nessun limite a indicizzazione. |
noindex | Non mostrare la pagina nei risultati di ricerca. |
nofollow | Non seguire i link su questa pagina. |
none | Uguale a noindex, nofollow. |
noarchive | Non mostrare link “Copia cache” nella serp. |
nosnippet | Impedisce la visualizzazione dello snippet nella serp. |
notranslate | Non proporre la traduzione della pagina nella serp. |
noimageindex | Non indicizzare le immagini. |
Ora li devi implementare sul tuo blog o sito web. Da considerare la presenza del tag unavailable_after. Una variabile per non mostrare la pagina nei risultati di ricerca dopo la data e l’ora specificata in formato RFC 850.
Puoi implementare X-Robots-Tag lato htaccess per impostare le regole del meta tag robots ai file non HTML. Ecco un esempio di come può presentarsi il comando per noindex e nofollow sui Portable Document Format:
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>
Semplice: con questo tool puoi suggerire a Google quali sono le risorse che non deve prendere in considerazione. Perché, ad esempio, non costituiscono un valore reale per gli utenti e devono essere online solo per una questione di servizio. Come le pagine privacy. Oppure con le risorse dedicate ai media partner.
Se hai una pagina con collegamenti a clienti e collaboratori forse può essere il caso di mettere tutti i link in nofollow. Google deve vedere che esiste quella risorsa ma non è consentito dare valore in termini SEO a quei collegamenti. Quindi puoi usare il meta tag robots per dare informazioni specifiche. Ed evitare una possibile penalizzazione, dato che Mountain View non è d’accordo con queste pratiche.
Da leggere: cancellare una pagina da Google
Il passaggio è importante per ottenere il miglior risultato. Ricorda di lavorare in modo da semplificare la vita al motore di ricerca e di controllare che non ci siano blocchi con il meta tag robots sulle pagine che ti interessano. A volte, come con il robots.txt, basta una svista per ritrovarsi con risorse deindicizzate.





