Hosting WordPress preinstallato e gestito con il 50% di sconto. Scopri la promo
Il web scraping dei contenuti è la pratica che consente ai webmaster di estrarre da altre pagine internet ciò che è stato pubblicato. Al fine di ottenere un database di informazioni da utilizzare in vario modo, anche per fini illeciti come il furto dei contenuti da sfruttare per conto proprio.
Non è il massimo, vero? In realtà l’attività di web scraping – o più semplicemente raccolta dei dati – è una sorta di pesca a strascico su internet: alcuni programmi noti come scraper permettono di raschiare (questa è la traduzione in italiano del termine scraping, in inglese) la rete alla ricerca di informazioni utili. Il risultato: una quantità di contenuti importanti. Le implicazioni legali ed etiche però sono pesanti e puoi anche decidere di proteggere il tuo sito web dai ladri seriali di testi. In che modo?
Argomenti
Iniziamo questo percorso con una definizione concreta: il web scraping è l’azione di recupero automatizzato delle pagine internet alla ricerca di dati e informazioni utili a un determinato scopo.
Il tutto avviene attraverso dei programmi noti come scraper che analizzano il codice HTML (o altri linguaggi di markup) e raccolgono le informazioni in modo strutturato per creare diverse risorse. Come, ad esempio, database o archivi di informazioni allineate. Il tutto senza un esplicito consenso.
Il mondo del web scraping è particolarmente articolato e permette di ottenere dati differenti. Una delle opzioni comuni è il lavoro svolto sui contenuti testuali: bot automatizzati vanno alla ricerca di pagine web per estrapolare – in tempi estremamente rapidi rispetto ad altre soluzioni, tipo quelle manuali – ciò che è stato pubblicato da altri utenti per poter sfruttare in modo differente questo impegno. Fortunatamente, esistono anche dei metodi per difendersi dal web scraping selvaggio.
Da leggere: come si realizzano i contenuti generati dall’AI
Partiamo da un presupposto: non tutti i tipi di web scraping dei contenuti sono pensati per rubare il lavoro altrui. Esistono diversi motivi che spingono a utilizzare gli scraper in modo autorizzato ed etico. Ad esempio, si può fare web scraping dei prezzi sui vari ecommerce per determinati prodotti.
In questo modo è possibile fare un confronto tra i diversi valori e ottenere un benefit per chi acquista, oppure si decide di lavorare sul sentiment del pubblico estrapolando valori e contenuti delle recensioni. Altra ipotesi: analisi di mercato attraverso i dati che si ottengono con lo scraping.
In tutti questi casi non “rubiamo” contenuti per utilizzarli in modo fraudolento ma è chiaro che c’è anche chi lavora in questa direzione. Si inizia col fare un lavoro di aggregazione di notizie e informazioni in chiave content curation e si finisce con il collezionare contenuti che non ti appartengono.
Si tratta di una materia borderline, difficile da definire in modo definitivo. Di base, non è un’attività vietata o illegale in Italia ma ci sono diversi paletti da considerare e che potrebbero rendere alcuni aspetti di quest’attività in contrasto con la legislazione vigente. Partiamo da un concetto base: se le informazioni sono accessibili al pubblico, l’attività di scraping è legale. Se invece richiedono il login vuol dire che hai accettato i termini di servizio.
I quali potrebbero vietare quest’attività, introducendoti automaticamente in un illecito. Senza dimenticare che il web scraping può andare contro normative come GDPR e CPRA degli USA che regolano proprio il come si raccolgono e utilizzano i dati personali anche sui siti web.
Poi c’è una questione di copyright da analizzare: stai facendo web scraping dei contenuti, come li userai? Stai prendendo testi e immagini in abbondanza, per fare cosa? Questi contenuti possono essere riutilizzati per aderire alla tua idea? Come puoi ben intuire, i rischi sono importanti.
C’è un altro aspetto da considerare: l’interrogazione attraverso lo scraping di un sito web può comportarne il downtime, con relativi danni economici: compromettere le prestazioni o la disponibilità di un sito internet può essere considerata un attacco informatico. Un po’ come avviene con un DDos.
Bisogna monitorare con attenzione i parametri legali indicati: se vuoi iniziare a fare web scraping devi essere sicuro di poter lavorare al netto di eventuali ripercussioni da parte degli avvocati dei siti web interessati e degli utenti ai quali hai preso i dati. Anche l’analisi del robots.txt è necessaria per verificare se ci sono dei parametri che vietano determinati scraping. Poi devi utilizzare un programma o uno script per estrarre dati da pagine web: si tratta di un software scraper, ne esistono diversi anche se Python è il linguaggio di programmazione più utilizzato grazie alla varietà di librerie.
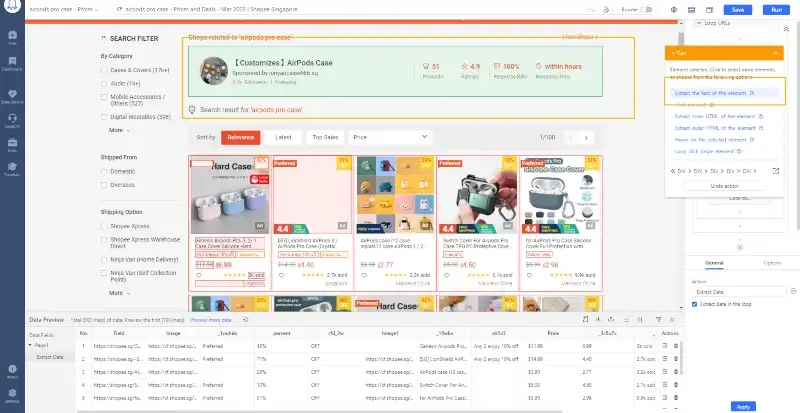
Tra i tool noti per estrarre informazioni online abbiamo Scrapy, framework open-source basato proprio su Python e adatto a progetti di scraping su larga scala. Molto buono anche Diffbot che usa l’intelligenza artificiale per analizzare e strutturare i dati delle pagine web. Octoparse, invece, è ideale per chi cerca modelli predefiniti da utilizzare su siti come Amazon, eBay e Twitter. Così è possibile lavorare proprio sull’estrazione di prezzi e trend.
Possiamo fare riferimento alle indicazioni del Garante della Privacy per tutelare un sito internet dalle azioni di web scraping con applicazioni basate sull’intelligenza artificiale. In primo luogo, se hai delle aree che non vuoi far scansionare c’è un solo modo per tutelarle: creare un’area riservata, che può essere visualizzata dopo aver fatto login con username e password. Poi si passa all’aggiornamento delle clausole di servizio. Secondo il Garante,
L’inserimento nei Termini di Servizio (ToS) di un sito web o di una piattaforma online dell’espresso divieto di utilizzare tecniche di web scraping costituisce una clausola contrattuale che, se non rispettata, consente ai gestori di detti siti e piattaforme di agire in giudizio per far dichiarare l’inadempimento contrattuale della controparte.
Il monitoraggio della rete e del traffico che arriva sul tuo sito web è sempre fondamentale: in questo modo puoi evitare che ci siano flussi di traffico anomali che sono sinonimo, spesso, di web scraping. Aggiungere dove servono dei CAPTCHA, usare dei programmi di honeypot e delle indicazioni utili nel robots.txt è fondamentale per aumentare la sicurezza di WordPress. Inoltre, per evitare lo scraping manuale puoi disabilitare il tasto destro.
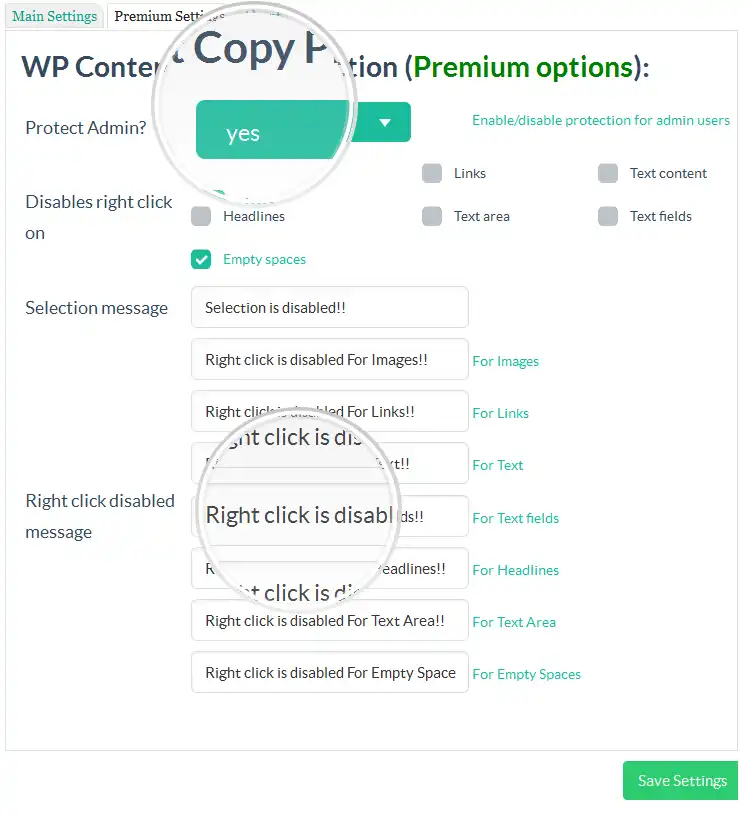
Ciò significa annullare la possibilità di evidenziare il contenuto per fare copia e incolla dei testi. In che modo? Usando WP Content Copy Protection & No Right Click ottieni un buon risultato ma è sempre l’hosting a essere un ulteriore campanello d’allarme per gestire grandi quantità di traffico anomalo.
C’è solo un dettaglio da ricordare: valuta con attenzione eventuali azioni per contrastare il web scraping. Intervenendo su robots.txt e sezioni chiuse al pubblico c’è il rischio di minare anche il crawling dei motori di ricerca. E di app utili per portare traffico al tuo sito web come ChatGPT.






2 commenti presenti
Luigi Celentano ha commentato il 2025-04-25 19:39:10
Ho letto con molto interesse il tuo articolo avente per oggetto il _web scraping_ di cui sono stato personalmente vittima recentemente. In proppsito mi farebbe piacere avere un colloquio con te per approfondiresoprattutto l’argomento di come difendersi.Vorrei chiederto consigli.
Riccardo Esposito ha commentato il 2025-04-28 08:32:27
Ciao Luigi, mi dispiace per la disavventura che hai affrontato. Non posso aiutarti in via privata ma se vuoi lasciare qualche domanda puoi utilizzare questi commenti e ti risponderò pubblicamente cercando di esserti d’aiuto.